Single-Core Equivalence
Multicore technologies in embedded computing systems pose new challenges in real-time application design that arise because of temporal coupling between processing cores. This coupling arises because of the shared cache, main memory, and I/O in the multicore architecture, which can result in loss of composability. In other words, when two components are composed, the effect that one has on the performance of another can be significant, resulting in very pessimistic worst-case performance.
The main contribution of the proposed work is to develop analysis techniques and resource management mechanisms for highly composable multicore systems with high schedulability. In such a system, the performance of one component should be isolated from pathological interference from other components over shared resources. This requires identifying and developing mechanisms to eliminate the root cause of poor worst-case behavior in the presence of component interactions. Moreover, the performance of the composed system should be easily analyzable. To eliminate undesirable interactions, we partition the memory, I/O and CPU resources for different applications in a coherent way. We call such a partition a Single-Core Equivalent Virtual Machine (SCEVM). The proposed work solves the problem of how to implement and optimize composable SCEVMs, including the allocation of memory, CPU and I/O resources, as well as how to compose them in a way that maximizes schedulability.
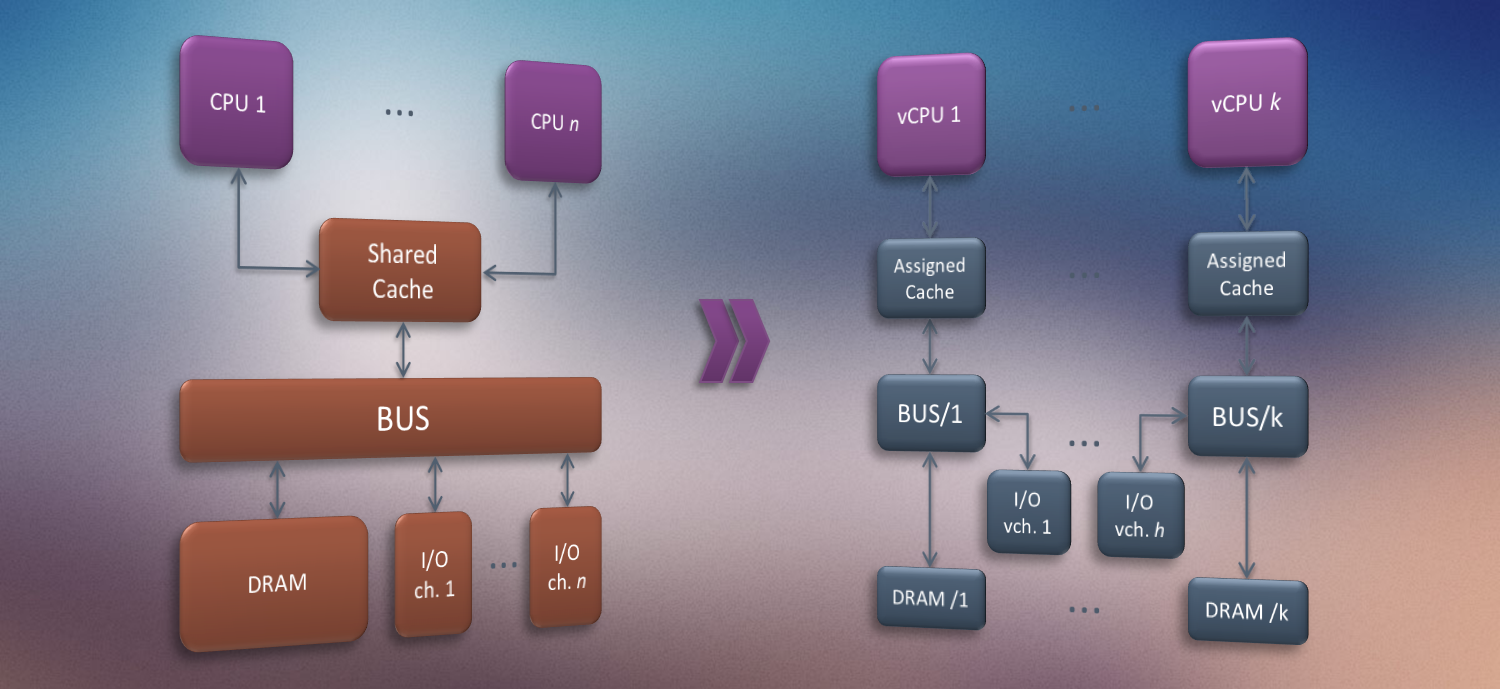
The techniques developed in this framework aim at solving the problem of interference that impairs predictability and significantly degrades worst-case bounds in multicore architectures, hence precluding the efficient use of multicore chips in mission-critical and safety-critical systems. The work is intended to serve as an integrated temporal and spatial isolation mechanism for multicore real time and embedded systems using widely adopted static priority scheduling method such as Rate and Deadline Monotonic Scheduling, which are supported by the IEEE real time computing standards. We build on ideas in performance isolation developed in the context of the Integrated Modular Avionics (IMA) architecture for single core chips. IMA offers a resource partitioning mechanism and requires that both logical and temporal faults in an IMA partition be contained within the partition. From a real-time computing perspective, IMA creates a set of temporal partitions, called real time virtual machines (RTVMs), which are scheduled by a low-level TDMA scheduler. Within each RTVM, applications are scheduled using static priority scheduling algorithms (e.g., rate- or deadline-monotonic scheduling). The IMA architecture, however, was not designed for multicore systems and several interference-related and concurrency-related challenges that are inherent to the multicore architecture need to be solved.
These challenges motivate our research and are enumerated below:
- Reducing undesirable cache and memory interactions: The DRAM, the memory driver, and the last-level cache are all shared among cores in a multicore architecture. While the shared resources at each layer can be partitioned, we need to not only develop a coherent set of partitioning mechanisms but also develop the real-time scheduling theory that can account for the effect of multiple layers of partitioning.
- Reducing undesirable I/O interactions: I/O activities in different cores could collide with each other over shared channels. Techniques used to resolve I/O conflicts used by IMA in a single core cannot be extended to multicore systems without severe limitations. New mechanisms are needed for I/O isolation in a multicore environment (that do not impact application code).
- Composable Analysis: Minimizing the undesirable interactions between RTVPs leads to significantly improved schedulability of the entire system. An optimization problem can now be defined that produces a highly efficient partitioning of memory bandwidth, last-level cache, and core scheduling in such a way that significantly improves feasibility of meeting deadlines and other constraints on all cores. In multicore systems, a task’s WCET depends on the size of memory bandwidth partitions and the size of the last-level cache partitions. To find the optimized size of these partitions, we need to know the WCETs’ impact on schedulability. We break such circular dependency in multicore storage-schedulability optimization by using a mathematical programming technique that can use only period information first to identify the maximal permissible WCETs size for each task. This allows us to determine the minimal required storage resource partition sizes. Once a feasible initial solution is found, mathematical programming approach allows us to jointly optimize the shared storage allocation and core schedulability subject to I/O constraints.
Each challenge has been addressed by a particular technique. The set of techniques, combined together are able to provide Single-Core Equivalence. Specifically, the fundamental bricks of the SCE framework are:
- MemGuard: a DRAM memory bandwidth reservation mechanism.
- PALLOC: a DRAM bank-aware memory allocator that can selectively allocate memory pages of each application on the desired DRAM banks to eliminate bank conflicts.
- Colored Lockdown: a flexible and deterministic last-level CPU cache allocation mechanism.
- Data Core: a technique to separate concerns about data loading to/from I/O devices and core computation.
A complete description of Single-Core Equivalence technology is available here: SCE Tech Report.
The listed techniques are briefly described below.
MemGuard
Memory bandwidth in modern multi-core platforms is highly variable for many reasons and is a big challenge in designing real-time systems as applications are increasingly becoming more memory intensive. MemGuard is an effcient memory bandwidth reservation system providing stronger memory performance isolation. MemGuard distinguishes memory bandwidth as two parts: guaranteed and best effort. It provides bandwidth reservation for the guaranteed bandwidth for temporal isolation, with effcient reclaiming to maximally utilize the reserved bandwidth. It further improves performance by exploiting the best effort bandwidth after satisfying each core\'s reserved bandwidth. MemGuard is implemented in Linux kernel and ported to several platforms: Intel, ARM, and PowerPC based platforms. Evaluation results with SPEC2006 and synthetic real-time benchmarks demonstrate that it is able to provide memory performance isolation with minimal impact on overall throughput.
Related Paper
MemGuard: Memory Bandwidth Reservation System for Effcient Performance Isolation in Multi-core Platforms, RTAS, 2013
Slides
PALLOC
PALLOC is a kernel-level memory allocator that exploits page-based virtual-to-physical memory translation to selectively allocate memory pages of each application to the desired DRAM banks. The goal of PALLOC is to control applications\' memory locations in a way to minimize memory performance unpredictability in multicore systems by eliminating bank sharing among applications executing in parallel. PALLOC is a software based solution, which is fully compatible with existing COTS hardware platforms and transparent to applications (i.e., no need to modify application code.)
Related Paper
PALLOC: DRAM Bank-Aware Memory Allocator for Performance Isolation on Multicore Platforms , RTAS, 2014
Slides
Colored Lockdown
We propose a novel, highly efficient deterministic cache allocation strategy called Colored Lockdown. The key idea of the proposed Colored Lockdown is to combine two techniques (coloring and lockdown) that have been proposed in the past, exploiting the advantages of both of them but mitigating their disadvantages. In particular, we use (a) coloring to optimize the packing in cache of those memory pages which are frequently accessed (this can be done by re-arranging physical addresses); then, we use (b) lockdown to override the behavior of the cache replacement policy to make sure that what has been allocated, on behalf of a given task, will not be evicted while that task is running. It is important to note that, in the proposed solution, cache allocation is deterministically controlled at the granularity of a single memory page and that it is independent from the specific cache replacement policy.
Related Paper
Access related paper here: Real-Time Cache Management Framework for Multi-core Architectures